

Avoiding Memory Exploits in Rust
Rust has revolutionized high-performance systems programming. Yet nevertheless, exploit upon exploit has popped up over the years leveraging insecure memory usage in Rust programs. I know what you’re thinking, isn’t the whole point of Rust that it isn’t vulnerable to the kind of memory exploits that historically have plagued C and C++ applications?
And the answer would be, kind of.
While Rust’s memory model is a massive improvement over C, there are still situations where the borrow checker can’t understand something we need to do, so we have to bypass it to access a raw pointer. Other times, we need to interact with C code that gives us a raw pointer, and Rust won’t let us dereference that outside of unsafe code. And although these situations are becoming rarer every year as the Rust compiler continues to advance, such problems still regularly arise.
Consider the following vulnerabilities that arose from unsafe code in major Rust libraries that turned out to be trivially exploitable with basic fuzzing techniques.
- Rust Standard Library vulnerable for years (2018)
- Claxon memory disclosure (2018)
- Heap buffer overflow in lz4_flex (2020)
- Stack overflow in prost (2018)
And that’s barely scratching the surface of the thousands of unsafe Rust exploits that have led to zero days.
Let’s look at one of these vulnerabilities and see if you can spot what’s wrong.
unsafe { buffer.set_len(new_len); }
Any ideas? When we allocate the buffer, we aren’t zeroing out the memory, so it contains (possibly sensitive) data from previous buffers in the program. To fix it, the developers merely added a second argument to buffer.set_len signifying that the memory should be cleared. Consider the following vulnerabilities that arose from unsafe code that turned out to be exploitable.
Maybe you think you’re safe because you never need to write unsafe code in your day to day use of Rust. But every vulnerability listed above was from a Cargo package with thousands of users. So even if you diligently avoid unsafe code, or just don’t have use cases for it, there’s a good chance that Cargo crates in your project use it with gleeful abandon.
Considering memory exploits have even been found in the Standard Library, no code can ever be truly safe. However, that doesn’t mean you’re helpless. Protecting Rust code from memory exploits comes down to three strategies: dependency auditing, minimizing reliance on unsafe code, making unsafe code you have to use as safe as possible. In the sections below, we’ll explore how you can realize each of these goals.
Vetting Dependencies
Experienced devs can apply the usual dependency management wisdom from other languages you’ve worked with. Analyze dependencies and subdependencies. Basic security engineering tactics like reviewing dependencies to ensure they are actively maintained, and keeping the dependency chain reasonably sized, will still apply in Rust. But what Rust specific dependency management details should you know?
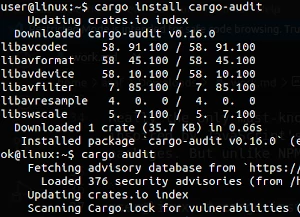
Really the only must-know is cargo audit. If you’ve worked with JavaScript before, this probably sounds familiar, and for good reason - it’s inspired by JavaScript’s npm audit command and works very similarly. It’s an automated tool that vets your entire dependency chain for vulnerable packages. But unlike NPM’s audit subcommand, Cargo’s audit has to be installed separately. Let’s take a look at it in action:
user@linux:~$ cargo install cargo-audit
Updating crates.io index
Downloaded cargo-audit v0.16.0
libavcodec 58. 91.100 / 58. 91.100
libavformat 58. 45.100 / 58. 45.100
libavdevice 58. 10.100 / 58. 10.100
libavfilter 7. 85.100 / 7. 85.100
libavresample 4. 0. 0 / 4. 0. 0
libswscale 5. 7.100 / 5. 7.100
Downloaded 1 crate (35.7 KB) in 0.66s
Installed package `cargo-audit v0.16.0` (executable `cargo-audit`)
ok@linux:~$ cargo audit
Fetching advisory database from `https://github.com/RustSec/advisory-db.git`
Loaded 376 security advisories (from /home/ok/.cargo/advisory-db)
Updating crates.io index
Scanning Cargo.lock for vulnerabilities (13 crate dependencies)
That’s it! Luckily, Rust dependency management is not harder than other languages, and cargo audit makes it as easy as a single command.
By the way, don’t be too confident by Rust’s principle that there is “no life before main”. Code in dependencies of dependencies (ad absurdum) can run arbitrary code no matter whether you call them or not.
One of the principles of Rust is no life before main, yet it’s still possible to run code before main by abusing how executables work.
Put in another way, it’s possible to run code without calling it.
It can be done by using the .init_array section on Linux or FreeBSD, __DATA,__mod_init_func section on macOS / iOS and the .ctors or .CRT$XCU sections on Windows.
That’s a quote from the famous essay by Sylvain Kerkour, Backdooring Rust crates for fun and profit (which, by the way, is another must read if you want to attain the next level of Rust security mastery). You can scour dependencies using grep to perform your own mini-audit, looking for these code patterns in code you depend on. If you find this functionality in dependencies, check out the project’s GitHub and raise an issue or try to find a good reason why they’re doing this. If you can’t find any solid justification, there’s a good chance it’s malware inserted as a backdoor for a supply chain attack.
Avoiding unsafe code
I know we’ve already discussed epic vulnerabilities that appeared in major Rust libraries, even including the standard library, but the reality is that 99% of the time, a memory exploit in your program will be caused by unsafe code written by you or someone in your team, not by a library maintainer or the Rust team. That’s why the best way you can avoid memory exploits in your code is to avoid using Rust’s unsafe capabilities insofar as it’s feasible.
However, before you strategize about introducing new unsafe code, you’ll want to take inventory of unsafe code already used in your project. Nothing sophisticated is necessary, a simple grep search should do the trick.
user@linux:~$ grep 'unsafe' -r .
./library/funcs/getAPI.rs: pub unsafe fn -> {
./library/mem/alloc.rs: return unsafe { buffer.alloc(512) };
./main/run.rs: unsafe { mov eax, 1; }
The Rust borrow checker continues improving radically, even as Rust itself has matured over the last several years. Often, code that used to need unsafe no longer needs it, and can be converted entirely to safe code. It’s also possible to keep some of the code unsafe, but move more functionality out of the unsafe chunk, making it as small as possible. This is most often the case when using inline assembly - try to only use inline assembly to accomplish things that absolutely cannot be accomplished via conventional Rust code.
For an excellent deep dive on the specifics of converting unsafe Rust to safe(r!) Rust, check out the seminal article Making Safe Things From Unsafe Parts
Mitigating the risks of unsafe code
Before you even consider writing or using unsafe Rust, make sure you have completely mastered it. Read the
Rustonomicon and
Learn Rust The Dangerous Way. If you don’t have the knowledge or time to acquire it, find someone on your team to guide you or hire a consultant. Copying unsafe Rust from StackOverflow, or trusting GitHub Copilot, is just not okay with the code uses the unsafe keyword. This isn’t something you can expect a beginner to do in production. If you’re hoping to use unsafe Rust to write inline assembly code or interface with a C library, it should go without saying that you should have access to expertise in those languages or be an expert yourself.
But if you do need to use unsafe code safely, you’ll want to fuzz it. Even if you’re convinced that you’ve robustly handled any possible input to your program, you’ll want to use a tool like Rust Fuzz to find loopholes. There’s an excellent book about fuzzing Rust programs, with the creative title Rust Fuzz Book. It’s a must-use tool for teams using unsafe Rust code. It’s not hard to use at all, even for beginners. Here’s a screenshot of the Rust Fuzz interface:

There are even tools more advanced than mere fuzzing, like SyRust, which uses state of the art computer science techniques to uncover previously well-hidden bugs. How deep you want to dive into this rabbit hole is up to you and your team, but fuzzing is probably good enough for teams desiring reasonably secure code that has minimal use of unsafe Rust.
Eliminating a real vulnerability
Enough basic tips, let’s apply what we’ve learned to remove a real vulnerability. First, we’ll search the codebase for unsafe code:
turtle@tech:~$ grep 'unsafe' -r .rust m1 assembly
./lib/m1_gpu.rs: unsafe {
Okay, let’s check out the unsafe code chunk in /lib/m1_gpu.rs and look for red flags:
#![feature(asm)]
// argN are provided via function arguments
let mut a: u64 = arg1;
let mut b: u64 = arg2;
unsafe {
asm!(
"add {0}, {1}",
inlateout(reg) a,
in(reg),
"device_load 1, 0, 0, 4, 0, i32, pair, r0_r1, r0_r1, 0, signed, lsl 1",
inout(reg) a,
);
}
Woah, what is that? I’m an experienced assembly programmer, and even for me that looks pretty mystifying. But Googling the code leads us to an article by the legendary M1 assembly hacker Alyssa Rosenzweig, showing us that this is in fact GPU assembly language for M1 macs. But even without a mastery of M1 assembly, we can see that the first addition operation is vulnerable to integer overflow, because the input and output numbers could be provided with negative values via Rust, and the assembly code doesn’t account for that.
This code was likely the symptom of a developer copying and pasting assembly code to make something work quickly, without thinking carefully about what the assembly was doing abstractly. Just a simple change removes the security weakness:
#![feature(asm)]
// argN are provided via function arguments
let mut a: u64 = arg1;
let b: u64 = arg2 + a;
unsafe {
asm!(
"device_load 1, 0, 0, 4, 0, i32, pair, r0_r1, r0_r1, 0, signed, lsl 1",
inout(reg) a,
);
}
Since the assembly code doesn’t even require b as an input, we can simplify our lives substantially by moving all possible functionality into Rust and out of assembly language. In this case, it removes a vulnerability, but even if we can’t see anything risky in assembly code, the best practice is always to do anything possible in Rust and only do minimal tasks in assembly.
Conclusion
Securing unsafe code is hard because it’s only needed for hard problems. Any task that goes beyond the capabilities of Rust’s borrow checker is likely to be a pretty advanced use case. But advanced cases are also usually the trickiest to secure. If you master unsafe code and minimize its usage, you can vastly reduce the risk associated with the unsafe keyword. Most developers should almost never need to use unsafe. Make sure you need it, if you think you need it you’re often wrong.
Making things more complicated yet, the variety of techniques recommended for mitigating risks in unsafe code can seem daunting. Fuzzing, auditing, consultants - but use the wisdom of the DevOps field by automating much of this work into your build pipeline. Junior devs shouldn’t need to manually fuzz code, after all. Gauge the complexity of your project to determine what security processes from this article you’ll need for your codebase, but any that you do implement should be integrated into already existing automated tests.
Armed with the understanding in this essay, we hope you’ll have a much easier time preventing exploits in your Rust projects.