With an ever-increasing number of developers attracted towards the file-based embedded database in their development environment, DuckDB has likewise developed its popularity as an embedded OLAP database.
Its column-oriented storage approach and vectorized execution makes it one of the quickest one in its category. Otherwise called SQLite for analysis, it is similar to SQLite in its design however varies in the type of workloads it handles. DuckDB is focused on OLAP workloads while SQLite is focused on OLTP.
Check out differences between OLAP and OLTP
Here are some of the features of DuckDB:
- Embedded single file database
- Easy setup (Just do pip install duckdb on python or install.packages(“duckdb”) on R to get started)
- Column store database with vectorized execution
- Supports fast analytical queries
- SQL
- Open Source
- Fully ACID
DuckDB is completely supported by a portion of the famous programming languages like C, C++, Java, Python and R. Other languages, like GO and Ruby, need the third party driver to work with DuckDB.
In this article, I will exhibit how to utilize DuckDB with R.
DuckDB with R
R is one of the popular languages for statistical analysis, visualization and reporting.
In order to get started with DuckDB in R, the first thing you have to do is to install DuckDB package.
Packages can be installed utilizing the packages explorer or by utilizing the install.packages command that R offers.
The package required for DuckDB is duckdb.
You can also use the following command to install duckdb package in R.
install.packages("duckdb")
R will automatically install another package DBI if not already installed as it is required for the communication between database and R
After installing the package, you need to load the installed package using the following commands:R
library(duckdb)
library(DBI)
Connecting to the database
There are two ways you can define the connection object for DuckDB in R, creating an in-memory database or connecting the database to a file where it can read from and write objects.
# In memory connection
con = dbConnect(duckdb::duckdb(), dbdir=":memory:", read_only=FALSE)
# Connection using a file
con_duck <- dbConnect(duckdb::duckdb(), "~/Path/To/Your/file.duckdb")
Let’s write some queries
DuckDB supports DBI methods like dbExecute() and dbGetQuery() to write queries and retrieve resultsets.
Queries like CREATE TABLE and UPDATE uses dbExecute() as it does not return any results, while queries like SELECT are executed using dbGetQuery() by storing the results in a variable.
Creating a table
Tables can be created in DuckDB in different ways.
We can use the standard CREATE TABLE statement by providing column names, using sub-query or using a CSV file.
SQL statements can be run using dbExecute method.
# dbexecute() to create table using CREATE TABLE statement
dbExecute(con, "CREATE TABLE countries (country_code VARCHAR, country_name VARCHAR, zip_code INTEGER);")
There is another method to create a table and load data into the table simultaneously.
DuckDB allows us to directly create a table utilizing a CSV file.
The data I am referring to is from
Kaggle.
So as to load that data in DuckDB, I have to pass the file path to the CSV file in the read_csv_auto method.
The database will automatically identify the column name and data type while creating the table.
Here is an example of how to create a table by straightforwardly utilizing a CSV file.
# Create table using CSV file
dbExecute(con, "CREATE TABLE COVID_DATA AS SELECT * FROM read_csv_auto('/Users/suresh/Desktop/COVID_DATA.csv');")
Inserting records
Similar to creating a table, inserting rows in the table can be done using INSERT INTO statement, or by directly loading from a CSV file.
# Inserting rows in the table
dbExecute(con, "INSERT INTO countries VALUES ('FR', 'France', 75116);")
# Loading records from CSV
dbExecute(con, "copy COVID_DATA FROM '/Users/suresh/Desktop/countries.csv';")
Querying the tables
We can use the dbGetQuery() method to run queries that return records and can print them using the print method offered by R.
Here are some examples on querying tables in DuckDB.
# Selecting all records from the table
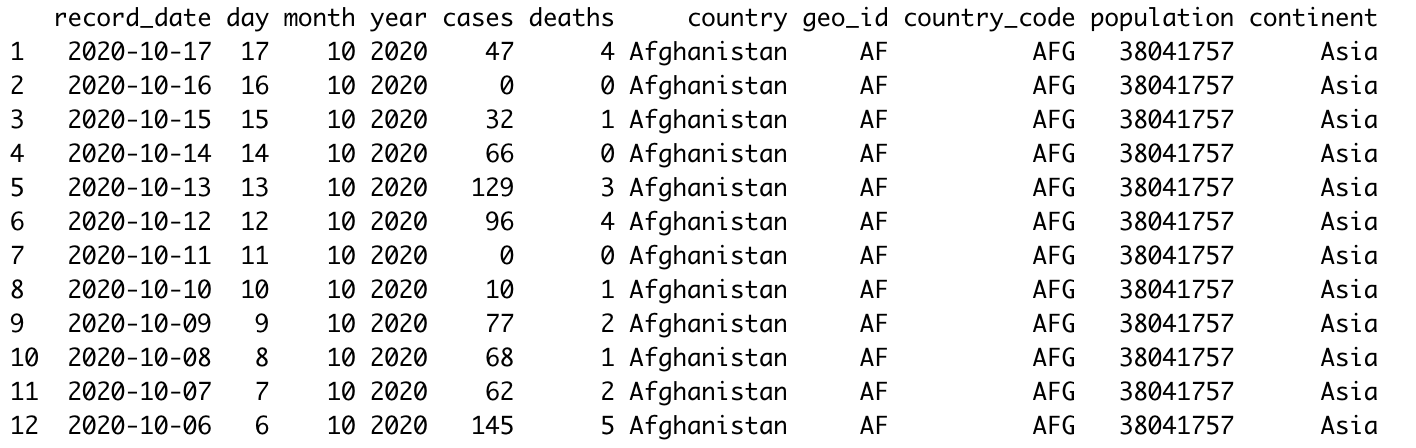
print(dbGetQuery(con, "SELECT * FROM COVID_DATA ;"))
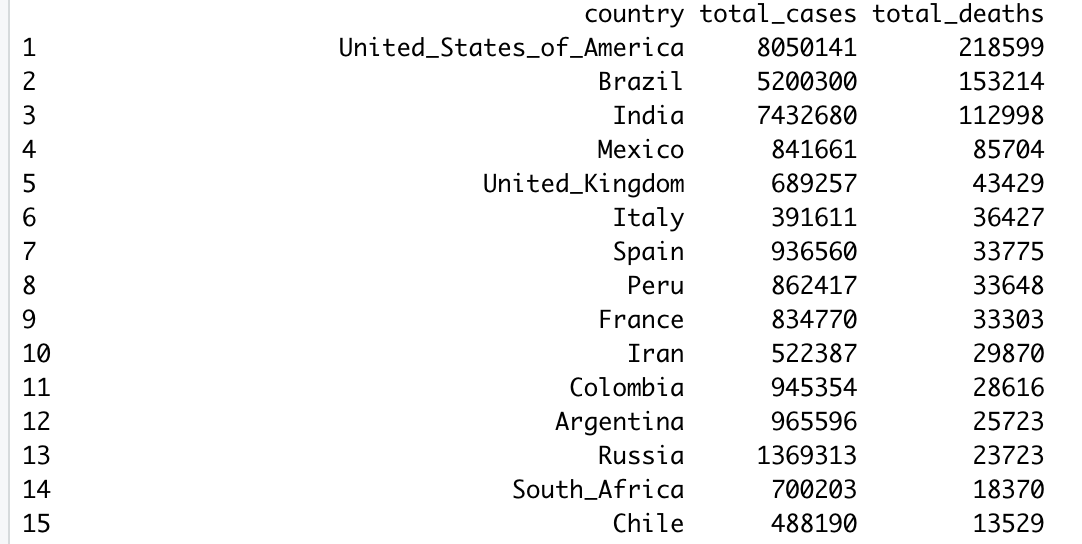
#Calculating total cases and total deaths by country and ordering them in descending order
print(dbGetQuery(con, "select countriesAndTerritories as country, sum(cases) as total_cases, sum(deaths) as total_deaths from COVID_DATA group by countriesAndTerritories order by total_deaths desc;"))
# Calculating average daily deaths by country
print(dbGetQuery(con, "SELECT country, round(avg(deaths),2) as average_daily_deaths FROM COVID_DATA group by country order by average_daily_deaths desc;"))

Joining tables
Let’s add two new tables “Courses” and “Offers”. This should be possible either by manually creating tables and adding records, or by making a table utilizing CSV file. I will show how to perform join in DuckDB.
Here are the structure and data of two tables.
Courses:

Offers:
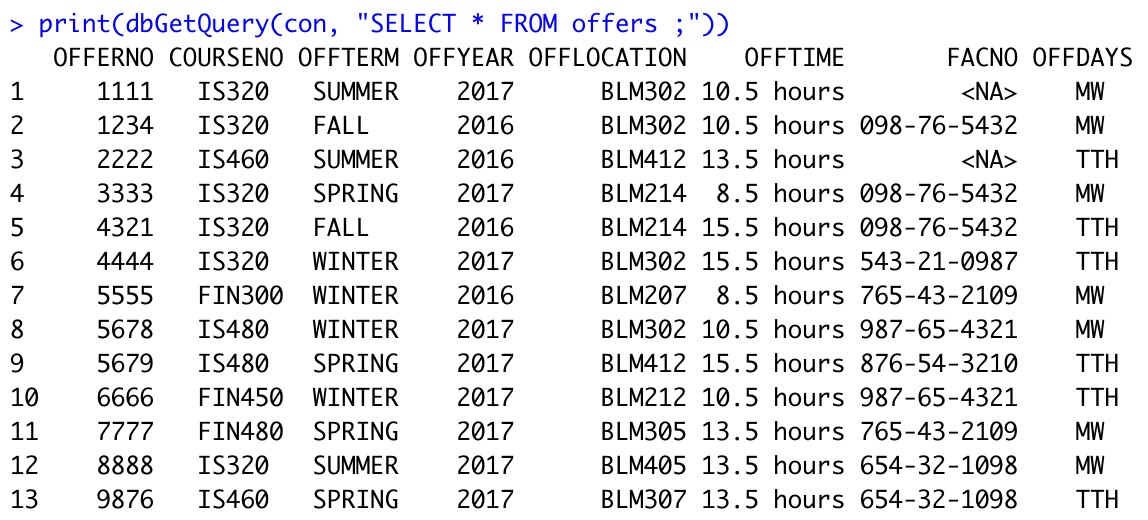
Now let’s join those two tables:
print(dbGetQuery(con, "SELECT C.COURSENO, C.CRSDESC, O.OFFTERM, O.OFFYEAR FROM COURSES C JOIN OFFERS O ON C.COURSENO=O.COURSENO;"))

Let’s add some aggregate functions to the join operation:
print(dbGetQuery(con, "SELECT SRC.COURSENO, SRC.CRSDESC, SRC.OFFTERM, SRC.OFFYEAR, COUNT(*) AS OFFERING_COUNT FROM (SELECT C.COURSENO AS COURSENO, C.CRSDESC AS CRSDESC, O.OFFTERM AS OFFTERM, O.OFFYEAR AS OFFYEAR FROM COURSES C JOIN OFFERS O ON C.COURSENO=O.COURSENO) SRC GROUP BY COURSENO, CRSDESC, OFFTERM, OFFYEAR ORDER BY OFFERING_COUNT DESC;"))

Some benchmarks
Inserting 50000 records in the table

Inner Join

Inner Join with aggregation and group by for few records

Aggregate function with the group by for large data

Complex COUNT query

Summary
These days, a lot of people perform data analysis tasks by using languages like R and Python. Using libraries Pandas and dplyr is pretty common. DuckDB makes it easy to perform data analysis tasks with SQL in a local development environment.
Hope you enjoyed the article! Feel free to comment or share.