

Introduction
In the previous article, we discussed the RASA NLU pipeline and its various components, in part 2 of this series we’ll look into the other major functionality of RASA which affects its core module that deals with the dialogue management part of a virtual assistant. You guessed it right I am talking about RASA policies. Numerous AI chatbots today don’t use as much AI as you would suspect. While it’s a regular practice to apply AI to NLU, with regards to dialogue management, numerous chatbot developers actually fall back to rules and state machines. Utilizing AI to choose the chatbots reaction presents an adaptable and versatile other option. The purpose behind this is one of the central ideas of AI: generalization.
At the point when a program can sum you up, you don’t have to hard-code a reaction. The model figures out how to perceive patterns based on the example conversations it has already seen. This scales in a manner hard-coded rule-based architecture never could. Rasa utilizes AI to choose the chabot’s next response depending on its trained model based on the example conversations. Rather than programming an if/else explanation for each conceivable discussion turn, you provide sample discussions to the model, to sum up from. What’s more, when you have to help another conversation pattern? Rather than attempting to reason through refreshing a current, mind-boggling, set of rules, you add examples to your training data that fit the new pattern. This methodology doesn’t simply apply to basic “to” and “fro” discussions—it makes it conceivable to help common sounding, multi-turn interactions.
Policies
When you implement a dialogue management solution, the main task is to decide on what happens next with respect to the conversation. The rasa policies choose which move to make at each progression in the discussion. One can choose numerous policies including the custom created policies, for a single rasa core Agent. yYet every step of the way. tThe policy which predicts the following activity with the most noteworthy certainty will be utilized. I have arranged a basic policy configuration for our bot.
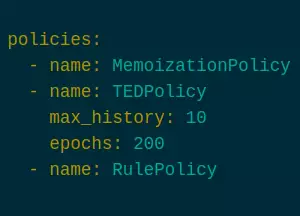
You can redo the policies your chatbot uses by indicating the policy key in your undertakings config.yml. There are various policies to browse, and you can use different policy combinations as per your requirements for a solitary chatbot. Here’s an illustration of what a list of policies in the config file may resemble:
policies:
- name: MemoizationPolicy
- name: TEDPolicy
max_history: 10
epochs: 200
- name: RulePolicy
To understand how each policy makes its decision about the next best action, read into the policy’s description below. Let’s deep dive into the policies we have for selection.
MAXIMUM NUMBER OF PREDICTIONS By default, your assistant can predict a maximum of 10 next actions after each user message. To update this value, you can set the environment variable MAX_NUMBER_OF_PREDICTIONS to the desired number of maximum predictions.
TED Policy
It’s a dialogue policy based on a transformer architecture, where the self-attention component works over the sequence of dialogue turns. Late work has utilized various hierarchical recurrent neural networks to encode different expressions in a dialogue context, yet it is contended that an unadulterated self-attention component is more appropriate.
Of course, an RNN accepts that each item in an arrangement is applicable for creating an encoding of the full sequence, however, a solitary discussion can consist of numerous covering talk sections as speakers interleave different points. A transformer picks which turns to remember for its encoding of the current dialogue state, and is naturally suited to specifically overlooking or taking care of dialogue history.
To understand this better let us take a look at what’s going on when the TED policy makes a prediction, from input to output. At every dialogue turn, the TED policy accepts three types of data as input: the client’s message, the past framework activity that was anticipated, and any values spared to the assistants’s memory as slots. Each of these is featurized and connected prior to being taken care of by the transformer.
Here’s the place where the self-attention mechanism becomes possibly the most important factor: The transformer gets to various pieces of the dialogue history dynamically at each turn and afterward evaluates and recalculates the significance of past turns. This permits the TED policy to consider a client expression at one turn yet disregard it totally at another, which makes the transformer helpful engineering for preparing dialogue histories. Next, a dense layer is applied to the transformer’s yield to get embeddings—numeric features used to inexact the significance of text—for the dialogue contexts and framework activities. The contrast between the embeddings is determined, and the TED policy boosts the comparability with the target labels and minimizes similarities with erroneous ones, a procedure dependent on the Starspace algorithm. This cycle of comparing the likenesses between embeddings is like the manner in which intent classification is predicted by the EmbeddingIntentClassifier in the Rasa NLU pipeline.
At the point when it’s an ideal opportunity to foresee the following framework action, all conceivable framework actions are positioned by their likeness, and the action with the most similarity is chosen.
Memoization Policy
The MemoizationPolicy recollects the stories from your training data. It checks if the current discussion is similar to a story in the training data. Assuming this is the case, it will anticipate the following activity from the coordinating story of your training data with a confidence score of 1.0. In the event that no similar training story is discovered, the policy predicts None with certainty 0.0.
When searching for a match in your training story, the strategy will consider the last max_history number of turns of the discussion. One “turn” incorporates the message sent by the client and any actions the chatbot performed prior to the current client message.
You can design the number of turns the MemoizationPolicy should use in your setup:
config.yaml
policies:
- name: "MemoizationPolicy"
max_history: 4
Rule Policy
In Rasa 2.0, it has really simplified dialogue policy configuration, drawn a clearer distinction between policies that use rules like if-else conditions and those that use machine learning, and made it easier to enforce business logic. In the earlier versions of Rasa, such rule-based logic was implemented with the help of 3 or more different dialogue policies. The new RulePolicy available in Rasa 2.0 allows you to specify fallback conditions, implement different forms and also map various actions to intents using a single policy. Rule policy has a new training data configuration, which allows you to very easily define the rules your assistant should follow. Refer the sample rule policy below which has a rule that will ask the user to rephrase the query in case of low confidence score.
rules:
- rule: Ask the user to rephrase whenever they send a message with low NLU confidence
steps:
- intent: nlu_fallback
- action: utter_please_rephrase
Policy Priority
For the situation that two policies predict with equivalent certainty (for instance, the Memoization and Rule Policies may both predict with certainty 1), the priority of the policy is thought of. Rasa policies have a default priority level that is set to guarantee the expected output on account of a tie. They resemble this, where higher numbers have higher priority:
Priority - Policy
6 – RulePolicy
3 - MemoizationPolicy or AugmentedMemoizationPolicy
1 - TEDPolicy
As a rule, it isn’t prescribed to have more than one priority for each level in your config. In the event that you have 2 policies with a similar priority level and they predict with similar certainty, the subsequent activity will be picked randomly. In the event that you make your own policy, utilize these priorities as a guide for sorting out the priority level of your custom policy. On the off chance that your arrangement is an AI policy, it should doubtlessly have priority level as 1, equivalent to the TEDPolicy.
Conclusion
In this article we talked about RASA policies and how effectively you can use them for your virtual assistants dialogue management skills. Feel free to try out various combinations that work best for your assistant.