

Introduction
In 2012 to resolve the data fetching challenges in facebook’s native mobile application, GraphQL was developed. It is an open-source query language for API, developed to overcome the performance bottleneck of REST. Over the years, it has become a popular and easier tool to utilize API and handle specific requests from client applications to get exactly what they need. It is an emerging technology and is being used by companies ranging from small, medium and large-scale including Instagram, StackShare, Twitter, Shopify etc.
Architecture of GraphQL
GraphQL server usually sits between the client application and data source and is responsible for handling the request from the client and returning the results. The architecture is transport-layer agnostic which implies that it can be used with any transport layer protocol. The data source can be a database, third party API or web services. GraphQL also does not care about the database or the format it is used to store the data. You can use a SQL database or NoSQL database as a data source.
GraphQL architecture can be divided into three main types:
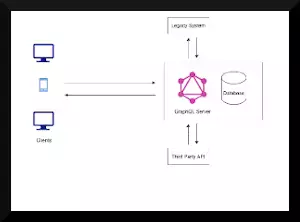
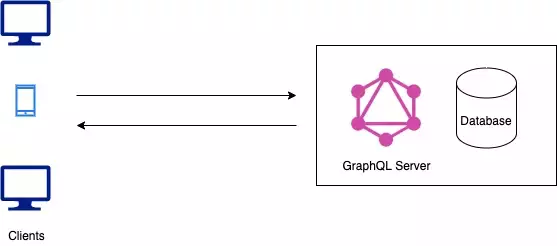
- GraphQL server with connected database:
This is especially suitable for a new project where you will have a database (SQL or NoSQL) which the GraphQL server can talk to. The GraphQL server processes the request from the clients, fetches the data from the database and returns the response to the client.
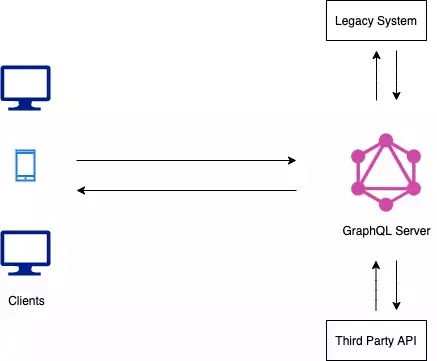
- GraphQL server with an existing Legacy system:
This architecture is useful for companies with legacy infrastructure and many APIs. On the off chance that you want to build a new product which needs to access the web services, multiple API’s of the legacy system, it would be hard to implement it. GraphQL server can act as a layer between the client application and those API and act as a shield and also hide the complexity. The client application can talk directly to the GraphQL server without interfering to the legacy application API.
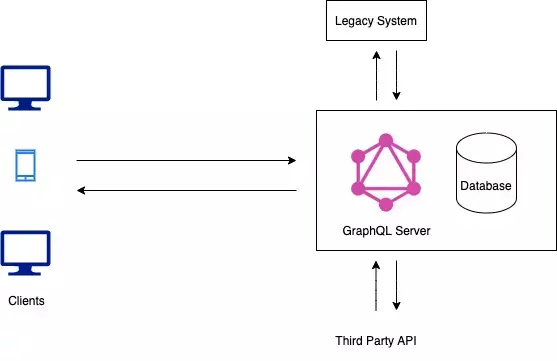
- Hybrid Approach:
This architecture is the mix of previous architectures. It will have a connected database and also will talk to the legacy system and to third party API’s. Once the GraphQL server receives a request from client application it will resolve the query and decide whether to ask the connected database for the result or get the results from the legacy system or third-party API’s
- Native GraphQL database:
At the time of writing (26/11/2020) there is only one known native GraphQL db server built by Dgraph that I know. Dgraph is a distributed graph database with native support for GraphQL engine. It is a solitary information base that provides native GraphQL executions to the developers to deal with. So as opposed to adding a layer between the traditional database framework and the GraphQLserver, developers can straightforwardly query a database that comprehends the request from GraphQL.
Core Concepts
Schema Definition Language(SDL)
Otherwise called IDL (Interface Definition Language), SDL is a language for writing schema in GraphQL. GraphQL mapping is a collection of types with fields. The specifications are defined in official GraphQL Specification Documentation. An example of GraphQL schema specification is given below
type Book {
id: String!
title: String!
publishedDate: DateTime!
author: Author @relation(name: "Books")
}
type Author {
id: String!
name: String!
books: [Book!]! @relation(name: "Books")
}
Querying
As the GraphQL lets the clients choose what information they need, clients need to send more data in the API request as a form of Query. Customers can determine the node they need to fetch information from or can follow edges to bring information about the assortment of hubs.
Here are an example query and result to show the login name and last two repositories from GitHub
Query
query {
viewer {
login
repositories(last : 2)
{
edges{
node{
name
}
}
}
}
}
Result
{
"data": {
"viewer": {
"login": "sureshrgmi",
"repositories": {
"edges": [
{
"node": {
"name": "exercise-python-json-parsing"
}
},
{
"node": {
"name": "Export_from_DB"
}
}
]
}
}
}
}
Mutation
A mutation is the queries used to modify data in the data store and are similar to REST methods like PUT and POST. Mutations can be used to do data operations like Insert, Update, Delete. The structure of mutation is the same as that of a query but starts with the keyword mutation. Let’s see an example of a mutation
Defining Mutation:
mutation CREATE_REPO_MUTATION ($input: CreateRepositoryInput!){
createRepository(input: $input) {
clientMutationId
}
}
Input Variable
{
"input": {
"clientMutationId": "1234",
"name": "TEST_REPO",
"visibility": "PUBLIC"
}
}
Query Result
{
"data": {
"createRepository": {
"clientMutationId": "1234"
}
}
}
Lets check whether the repo is created or not.
Query
query {
viewer {
login
repositories(last : 2)
{
edges{
node{
name
}
}
}
}
}
Result
{
"data": {
"viewer": {
"login": "sureshrgmi",
"repositories": {
"edges": [
{
"node": {
"name": "TEST_REPO"
}
}
]
}
}
}
}
GraphQL vs REST
The main advantage of the REST API is its simplicity, but this simplicity may turn out to be your main performance bottleneck in some cases. Rest endpoints are designed to return a fixed data structure where one endpoint does one task. Due to this, in most cases, developers have to face the scenario of over and under fetching. Over fetching is a case when API call returns information more than what is needed. Under Fetching is the case when developers have to perform multiple requests to get what they need.
Let’s take an example of GITHUB, If you want to get information about the user, repositories and followers, In REST, you need to call three different endpoints each for users/
Should I switch from GraphQL to REST?
Choosing one between GraphQL and REST always depends upon the use-cases and requirements of your project. There are use-cases where REST is a better choice and are also the cases where choosing GraphQL is more advantageous. If you have a project that is utilizing REST API and is performing fine, there is no need to worry about utilizing extra resources and implementing GraphQL. REST API is a matured product and has been here for a long time. For most of the applications, switching to GraphQL doesn’t mean that you will see huge performance improvement unlike Facebook where there are millions of queries being performed in a small amount of time. Also, if you are planning to create a new project and have to choose one between these two, I would suggest you to choose GraphQL. This is because of it’s obvious performance advantages over REST. So, As I already mentioned, choosing between one depends upon the requirements and would be better to analyze your project requirement before choosing one.




